Alibaba
Z-Image
Image
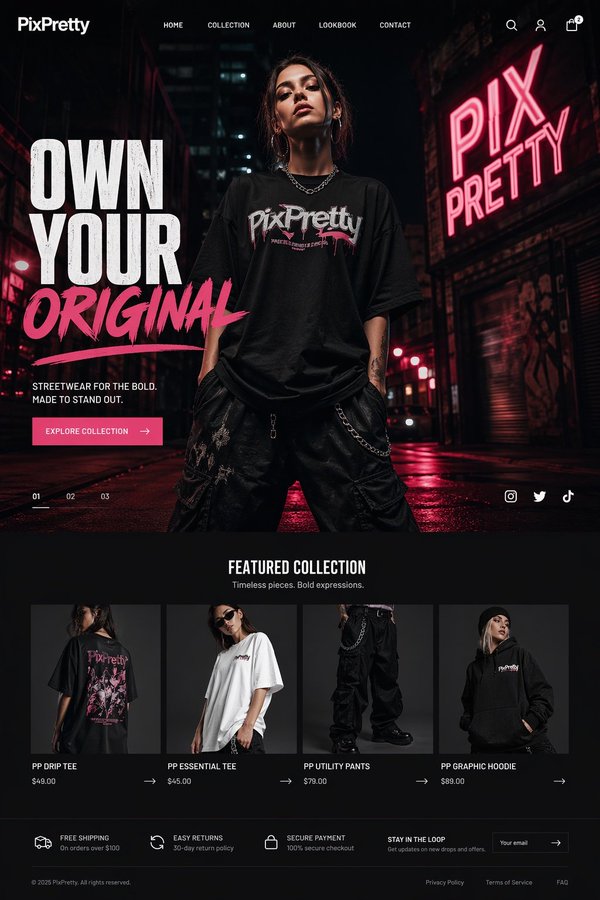
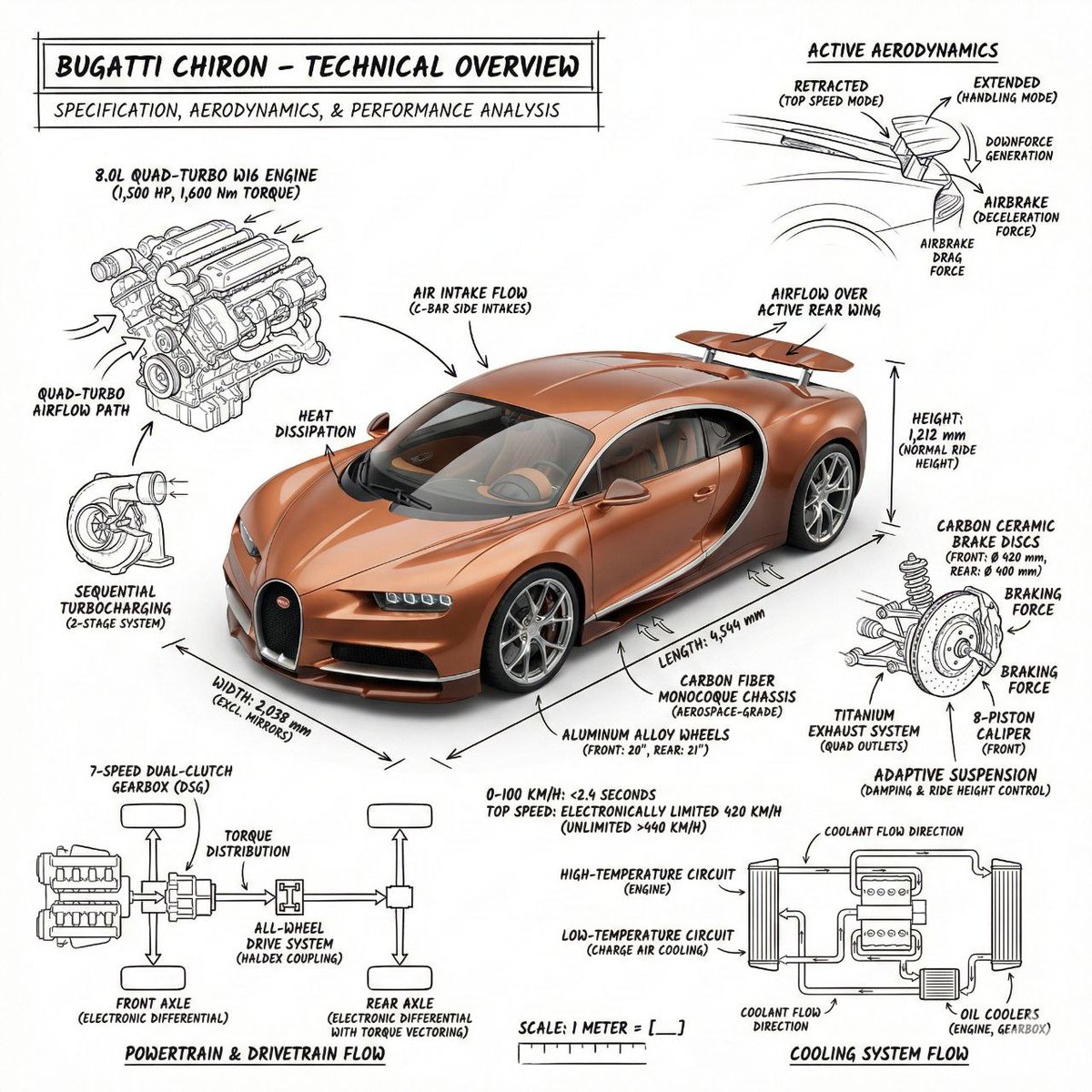
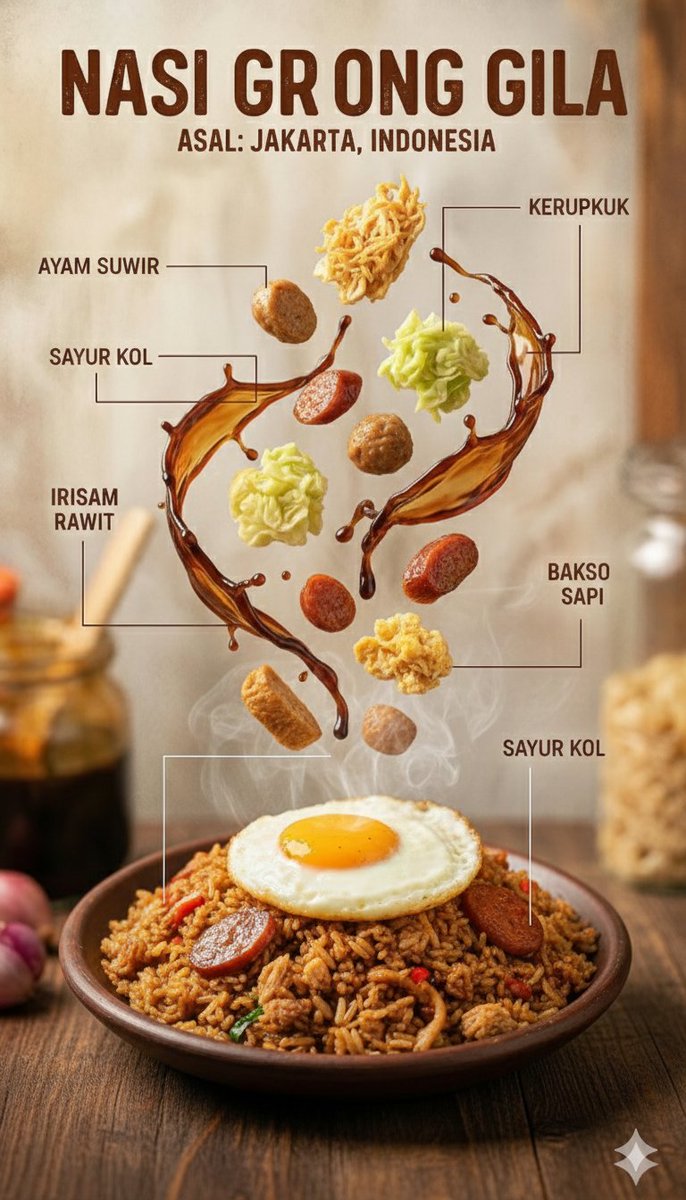
Alibaba's lightweight text-to-image model. Fast single-image generation with 5 aspect ratios — ideal for quick concept drafts and social media visuals at just 1 credit.
Why pick it
Lowest cost at 1 credit per generation
- Best for
- Cheap first-pass visual concepts
- Input
- Text
- Output
- Image
- Credits
- From 1 credit per generation
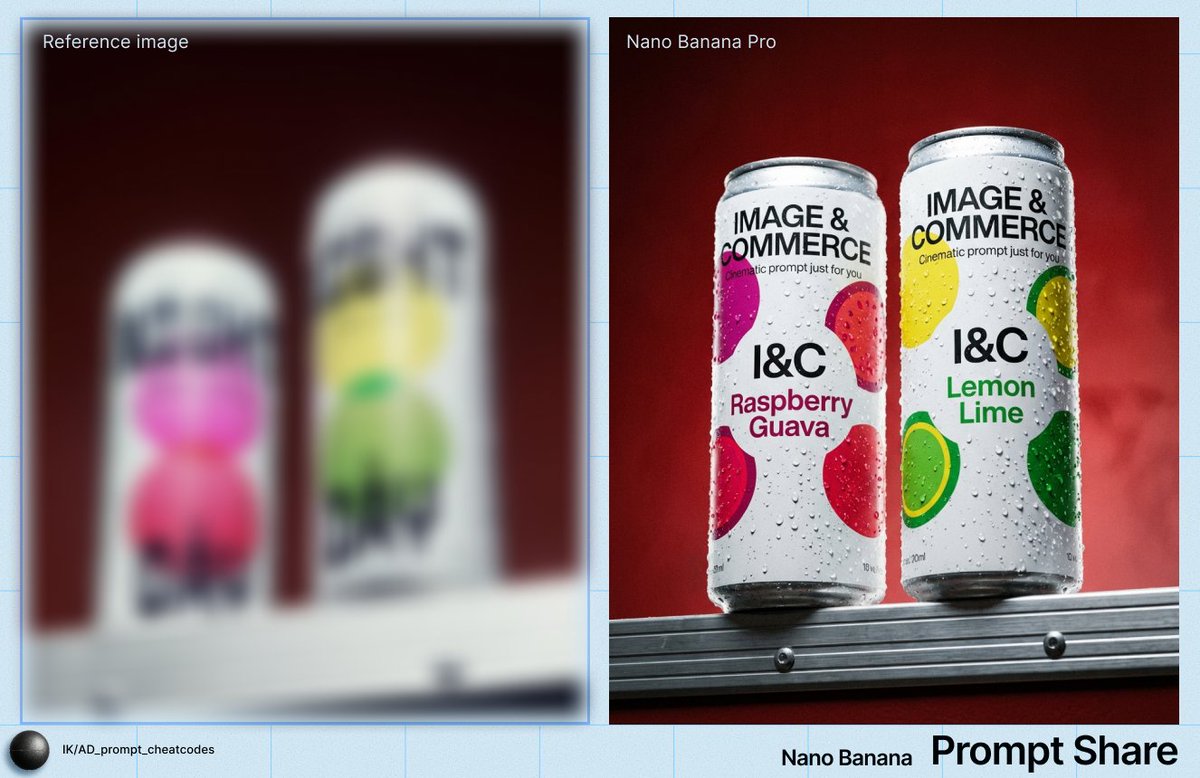
Fast single-image output for rapid iterationClean text-to-image with 5 aspect ratio presets