AI 模型目錄
先比較圖片、影片、音訊和聊天模型,再決定是否消耗點數
模型目錄
依任務、輸入和輸出查找模型
依模態、輸入類型、提供方、優勢和點數說明縮小範圍。開啟模型頁即可查看真實輸出、任務適配度和快速線上試用。
全部模型
可依模型、廠商、能力或任務搜尋,再用事實篩選縮小頁面範圍,不必逐一開啟詳情頁。
95 個模型選項
先比較輸入、輸出、點數和範例提示,再決定要放進候選清單的模型。
比較模型適配度
依 Rivya 已為每個模型追蹤的欄位篩選:模態和支援輸入。任務適配度則由模型內容來源顯示在卡片上。
點數提示
每張模型卡都會顯示來自目錄內容的點數說明。
模態
支援輸入
95 個模型選項
先比較輸入、輸出、點數和範例提示,再決定要放進候選清單的模型。
適合先看的模型
從這裡開始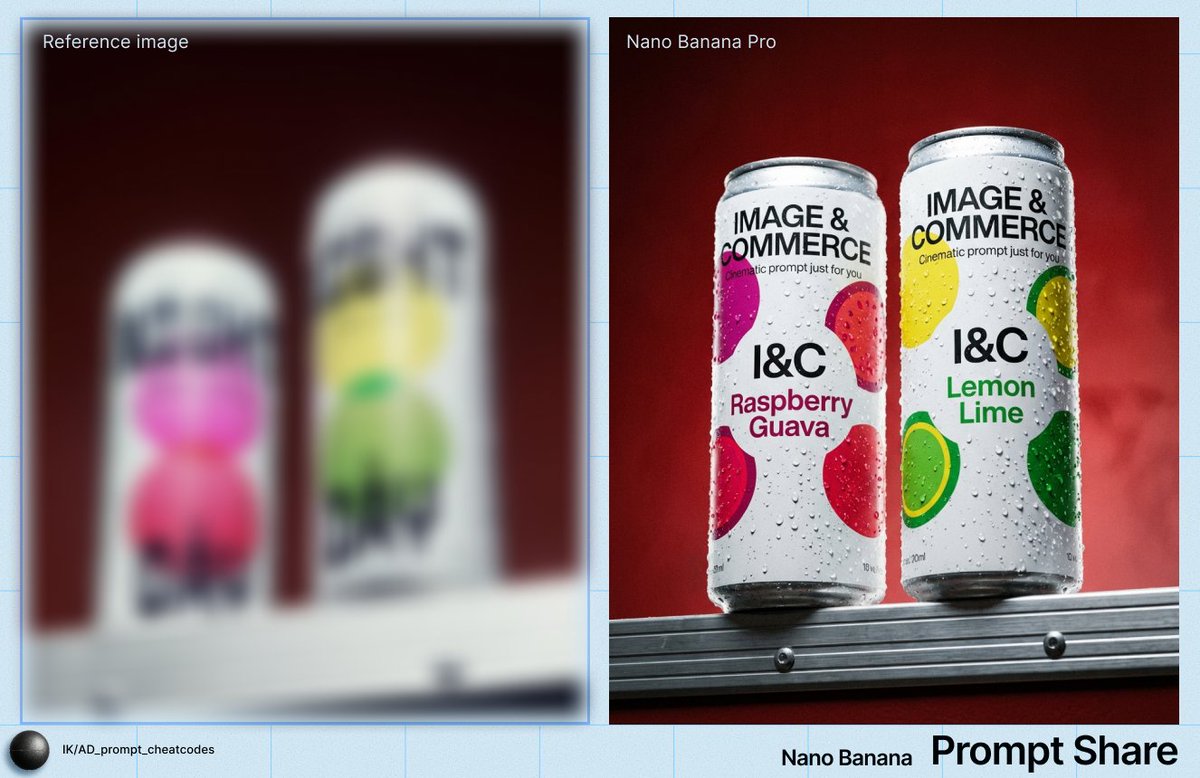


OpenAI
GPT-5.5
OpenAI 在 Rivya 上的進階 GPT 對話模型,適合在任務簡報需要更多推理空間時處理複雜推理、圖像輔助分析、研究統整和結構化寫作。
為什麼選它
複雜推理和多步驟分析的上限更高
- 最適合
- 跨越冗長或零散來源資料的研究統整
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按量付費 - 依使用量消耗點數
OpenAI
GPT-5.4
OpenAI 在 Rivya 上更高階的 AI 對話模型,具備更強的結構化輸入處理、推理控制和工具導向對話專案能力,適合更複雜的分析與寫作任務。
為什麼選它
更強的複雜分析和多步驟規劃
- 最適合
- 長篇策略 brief 和決策備忘錄
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
OpenAI
GPT-5.4 Codex
OpenAI 在 Rivya 上更高階的 Codex 模型,為要求較高的 repo 級開發專案提供更強的程式碼能力、結構化推理和工具導向協作。
為什麼選它
更高階的 Codex 推理和程式碼協作
- 最適合
- Repo 級除錯和架構審查
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按量付費 — 依使用量消耗點數
OpenAI
GPT-5.3 Codex
OpenAI 在 Rivya 上最新、能力最強的 Codex 模型。它結合最先進的程式碼生成能力與更深入的代理式推理,適合最嚴苛的開發專案。
為什麼選它
OpenAI 能力最強的程式碼模型
- 最適合
- 大型程式碼庫中的高難度除錯
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
OpenAI
GPT-5.2
OpenAI 在 Rivya 上的旗艦 AI 對話模型,具備進階推理、最多 6 張圖片的視覺支援,以及 20K 字元 context window。它是適合研究、規劃、寫作和圖片感知分析的強力通用 GPT 選項。
為什麼選它
進階推理和複雜分析
- 最適合
- 策略備忘錄和決策文件
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
OpenAI
GPT-5.2 Codex
OpenAI 在 Rivya 上更進階的 Codex 模型,為複雜工程任務提供更強推理。它針對長週期代理式編碼、架構決策,以及單純程式碼生成不足以處理的大型重構進行最佳化。
為什麼選它
複雜工程推理能力更強
- 最適合
- 架構審閱和系統設計取捨
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
OpenAI
GPT-5.1 Codex
OpenAI 在 Rivya 上升級版的 Codex 模型,具備更高程式碼準確度,也為代理式編碼任務提供更強推理。它保留同一個長輸出、理解 repo 的專案,同時改善多文件重構和更安全的程式碼編修。
為什麼選它
程式碼準確度優於 GPT-5 Codex
- 最適合
- 多文件重構和遷移
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
OpenAI
GPT-5 Codex
OpenAI 在 Rivya 上的 GPT-5 Codex 程式碼專用模型,適合除錯、實作規劃、重構,以及支援視覺理解的技術問題求解。
為什麼選它
程式碼專用,具備 12K output token 上限
- 最適合
- 程式碼審查和錯誤修復
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按量付費 — 依使用量消耗點數
Gemini 3.1 Pro
Google 在 Rivya 上最新、能力最強的 Gemini AI 對話模型。具備頂級推理、視覺能力和指令遵循能力,是高要求分析與創意任務中最強的 Gemini 選項。
為什麼選它
Google 能力最強的 Gemini 模型
- 最適合
- 長 context 研究資料包和比較工作
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
Gemini 3 Pro
Google 在 Rivya 上深度更高的 Gemini AI 對話模型。推理能力比 Gemini 2.5 Pro 更強,並支援視覺輸入,更適合研究綜整、技術寫作和更審慎的多模態分析。
為什麼選它
推理能力優於 Gemini 2.5 Pro
- 最適合
- 長篇分析和結構化建議
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
Gemini 3 Flash
Google 在 Rivya 上的新一代快速 AI 對話模型。token 成本比 Gemini 2.5 Flash 更低,推理能力也更強,專為高用量多模態對話、截圖分流和快速助理工作打造。
為什麼選它
所有對話模型中最低的 token 定價
- 最適合
- 快速多模態分流和截圖分析
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
Gemini 2.5 Pro
Google 在 Rivya 上更進階的 Gemini AI 對話模型。推理能力比 Flash 更強,支援視覺輸入和 20K context,適合研究綜整、文件分析和結構化寫作,每次使用 2 點數。
為什麼選它
推理能力比 Gemini Flash 更強
- 最適合
- 研究綜整和分析型寫作
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
Gemini 2.5 Flash
Google 在 Rivya 上最快、也最實惠的 AI 對話模型。每次使用 1 點數,並支援最多 6 張圖片的視覺輸入,適合快速問答、初稿摘要、截圖分流和日常 AI 協助。
為什麼選它
最低成本的對話模型,僅 1 點數
- 最適合
- 快速研究查詢和初稿摘要
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按次使用付費 — 點數依使用量計算
Anthropic
Claude Opus 4.7
Anthropic 在 Rivya 上的旗艦 Claude 聊天模型,適合深度推理、謹慎整合、主管寫作和高影響力文字工作。
為什麼選它
旗艦級文字推理和整合能力
- 最適合
- 主管備忘錄和董事會風格敘事
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按使用量付費 - 點數依用量計算
Anthropic
Claude Opus 4.6
Anthropic 在 Rivya 上的旗艦 Claude AI 聊天模型。它為深度推理、複雜分析和高品質寫作而設計,適合要求高、風險高的專案。
為什麼選它
旗艦級推理和複雜分析
- 最適合
- 主管備忘錄和高風險敘事寫作
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按使用量付費 — 點數依用量計算
Anthropic
Claude Sonnet 4.6
Anthropic 在 Rivya 上的均衡型 Claude AI 聊天模型。它保留強大的長文推理和謹慎分析,適合內容、研究和程式設計專案,同時不必直接跳到 Opus 層級的花費。
為什麼選它
可靠推理和均衡品質
- 最適合
- 審查長簡報、PRD 和策略文件
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按使用量付費 — 點數依用量計算
Anthropic
Claude Opus 4.5
Anthropic 在 Rivya 上的旗艦 Claude AI 聊天模型。它擅長深度推理、複雜分析和專家級寫作,是處理關鍵 AI 任務時的高階選擇。
為什麼選它
Anthropic 最強的模型
- 最適合
- 深度研究整合和困難分析
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按使用量付費 — 點數依用量計算
Anthropic
Claude Sonnet 4.5
Anthropic 在 Rivya 上的均衡型 Claude AI 聊天模型。它擅長細膩寫作、謹慎分析和注重安全的回應,是內容創作和研究中很穩的 Claude 選項。
為什麼選它
細膩寫作和謹慎分析
- 最適合
- 編輯式改寫和語氣敏感的寫作
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按使用量付費 — 點數依用量計算
Anthropic
Claude Haiku 4.5
Anthropic 在 Rivya 上的輕量 Claude AI 聊天模型。它針對速度、成本效率和穩定的日常聊天表現調整,適合想要 Claude 語氣但不想使用高階方案成本的高頻專案。
為什麼選它
更適合低延遲、高頻使用
- 最適合
- 收件匣分流和快速內部問答
- 輸入
- 文字
- 輸出
- 文字 / 推理
- 點數
- 按使用量付費 — 點數依用量計算
























Ideogram
Ideogram Character
面向角色一致性的選項,可把一張已核准的角色圖片延展到新場景、服裝和格式。當身份保留比廣泛圖片編輯更重要,且一次只需要一張輸出圖片時使用它。

Alibaba
Wan 2.2 A14B Turbo
Wan 2.2 A14B Turbo 目前在 Rivya 上同時涵蓋文字轉影片、圖片轉影片,以及由一張圖片加一段音訊驅動的影片路徑。現行價格為文字或圖片生成 `480p = 8`、`720p = 12`,圖片加音訊驅動時為 `480p = 16`、`580p = 20`、`720p = 24`。
Kuaishou
Kling 3.0 motion-control
更新一代的 Kling motion-control 選項,可用一張參考圖加一段動作影片驅動單一主體,並明確選擇背景來源。當你需要動作遷移,同時也想更強地控制場景應來自影片或圖片時,適合使用它。
Kuaishou
Kling 2.6 motion-control
這是專為動作遷移設計的專案,可用一張參考圖加一段動作影片驅動單一主體。當你想用較低成本完成 Kling motion-control 測試,且不需要 Kling 3.0 motion-control 額外的場景控制時,適合使用它。







