Alibaba
Z-Image
छवि
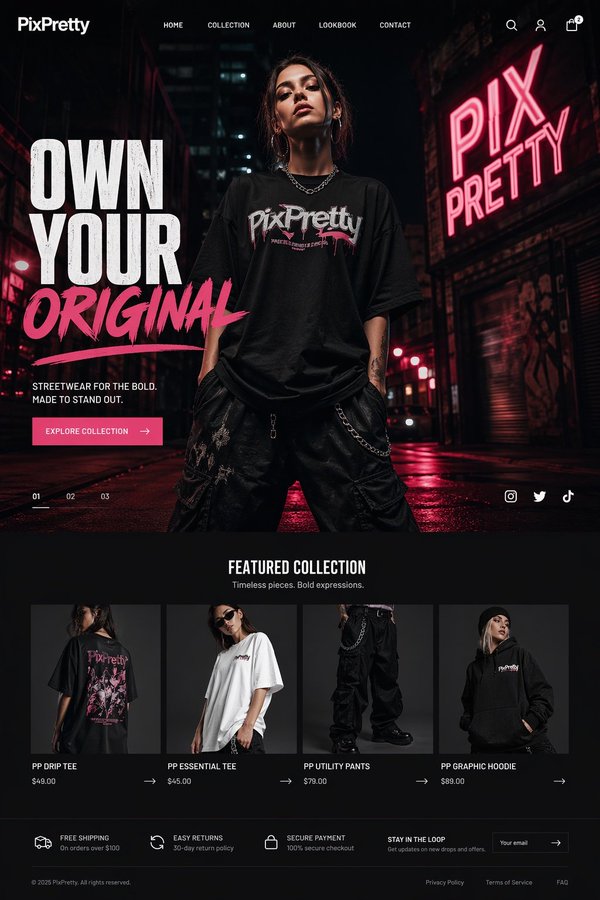
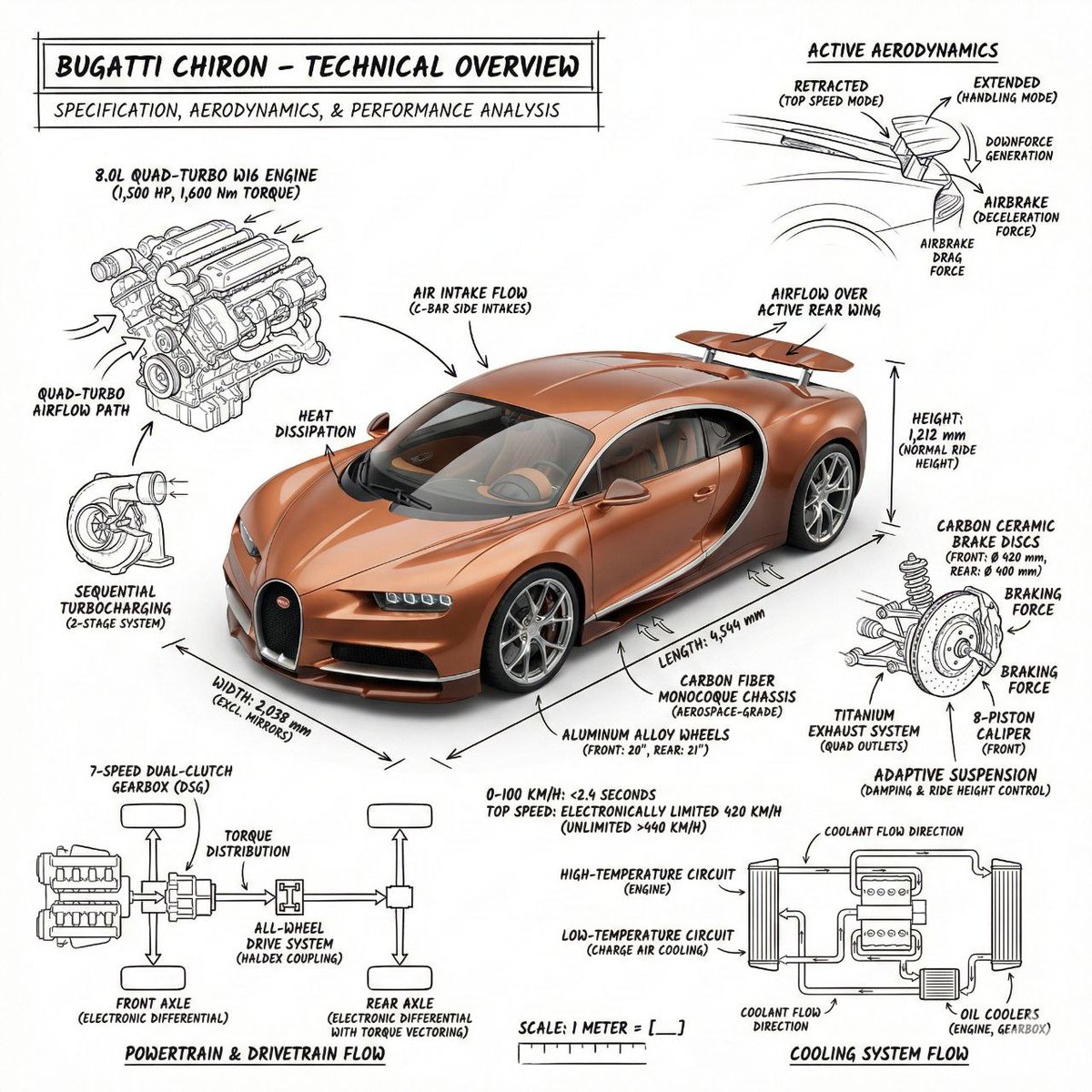
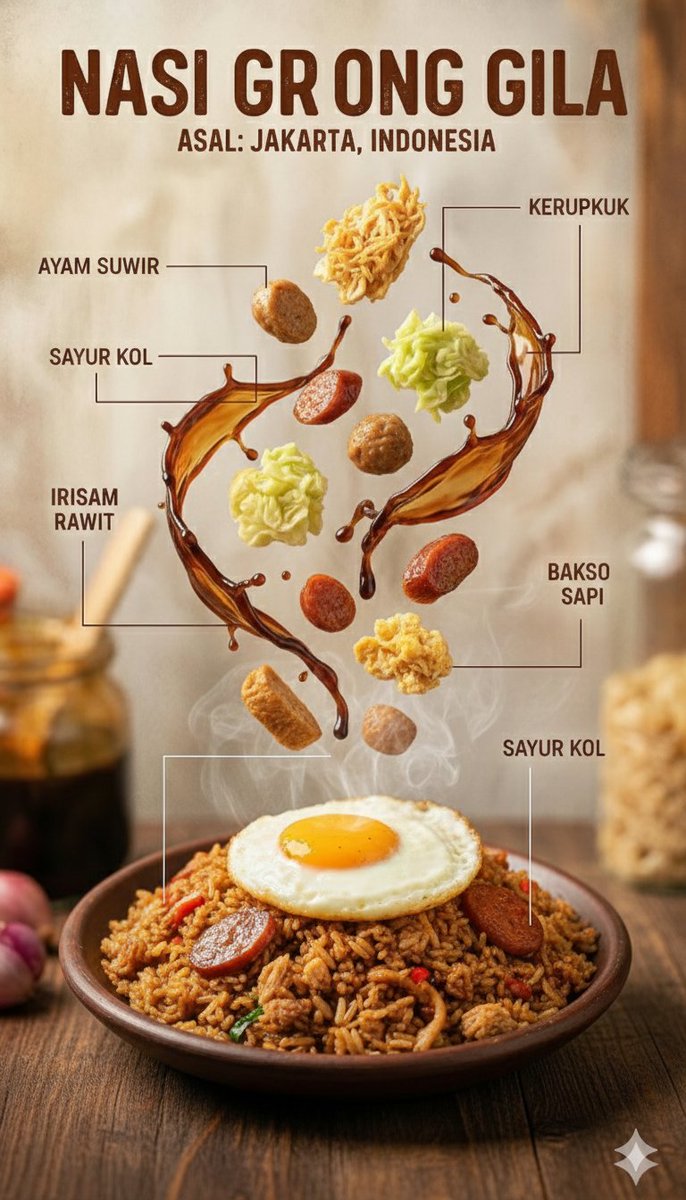
Alibaba का हल्का टेक्स्ट-से-इमेज मॉडल। यह 5 आस्पेक्ट रेशियो में तेजी से एक इमेज बनाता है और केवल 1 क्रेडिट में शुरुआती कॉन्सेप्ट तथा सोशल मीडिया विजुअल तैयार करने के लिए उपयुक्त है।
इसे क्यों चुनें
1 क्रेडिट प्रति जनरेशन में सबसे कम इमेज शुरुआती लागत
- इनके लिए उपयोगी
- कम लागत वाले शुरुआती विजुअल कॉन्सेप्ट
- इनपुट
- टेक्स्ट
- आउटपुट
- इमेज
- क्रेडिट
- 1 क्रेडिट प्रति जनरेशन से
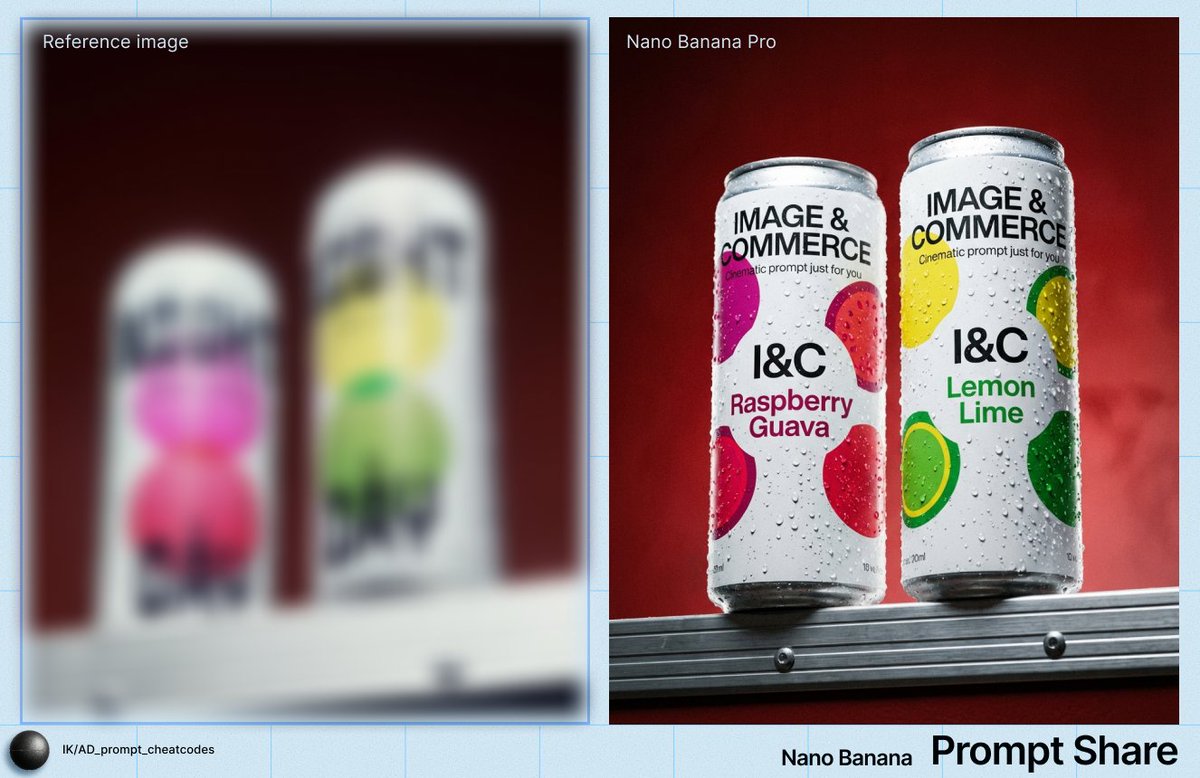
तेज पुनरावृत्ति के लिए शीघ्र एकल-इमेज आउटपुट5 आस्पेक्ट रेशियो प्रीसेट के साथ साफ टेक्स्ट-से-इमेज जनरेशन