Alibaba
Z-Image
รูปภาพ
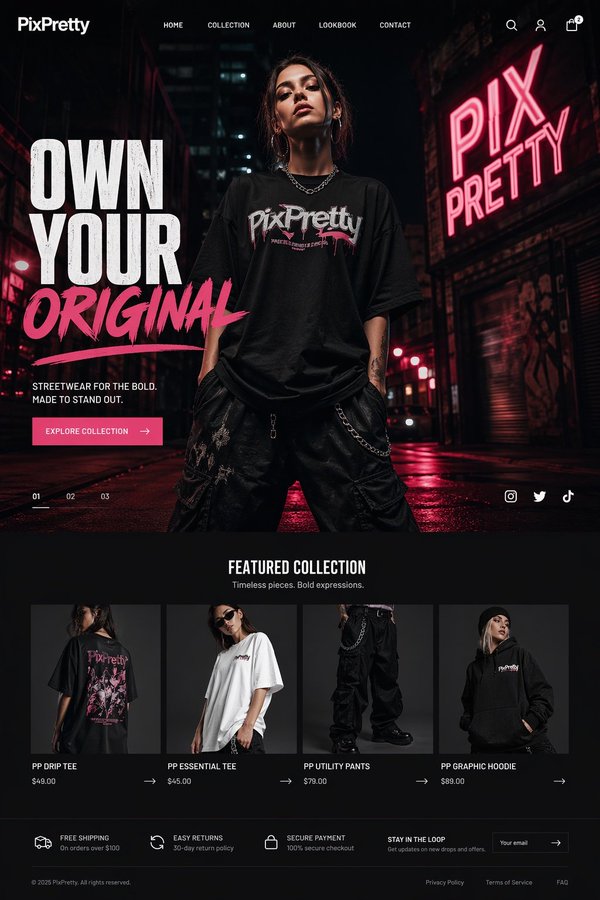
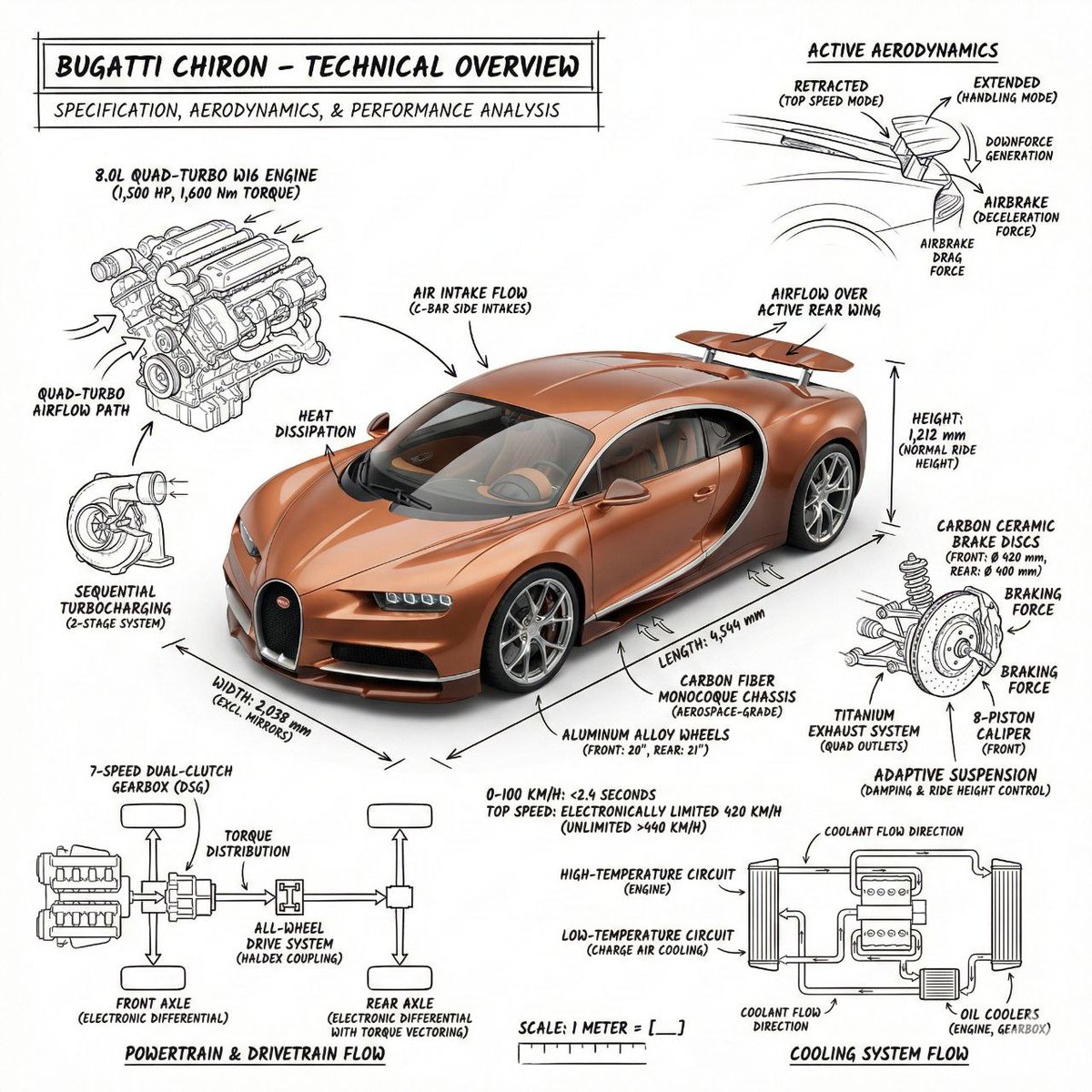
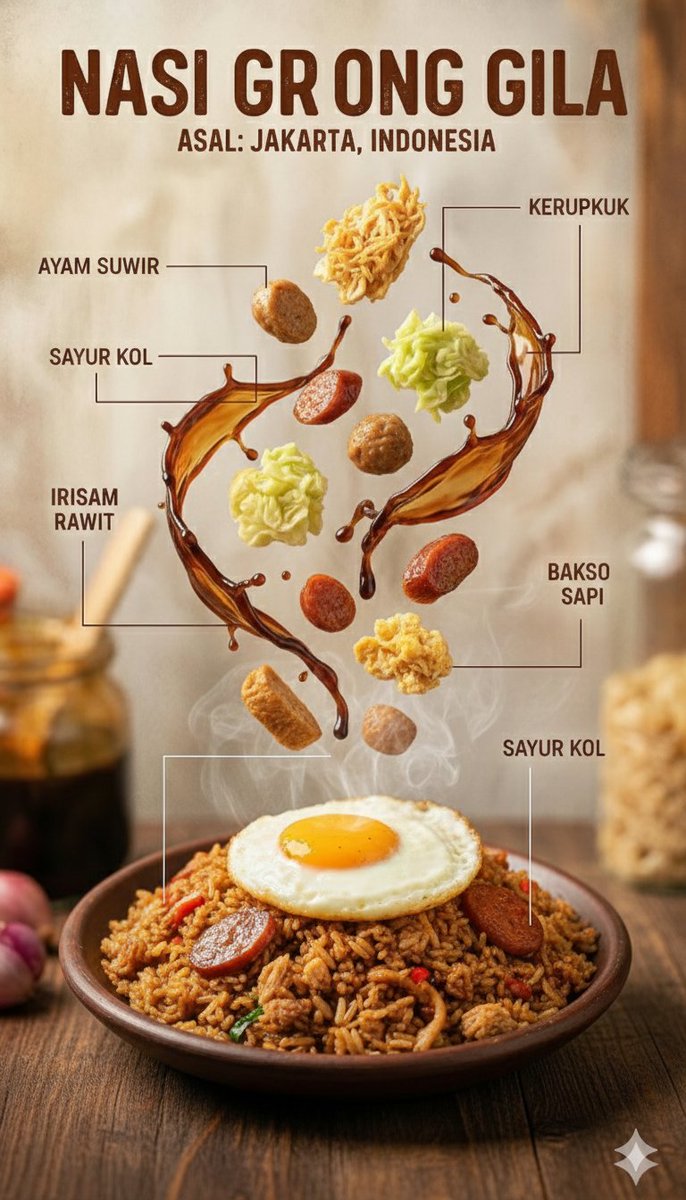
โมเดล text-to-image น้ำหนักเบาของ Alibaba สร้างภาพเดี่ยวได้รวดเร็วพร้อมอัตราส่วนภาพ 5 แบบ เหมาะกับร่างคอนเซปต์เร็วและภาพสำหรับโซเชียลมีเดียในราคาเพียง 1 เครดิต
ทำไมควรเลือก
ต้นทุนต่ำที่สุดที่ 1 เครดิตต่อการสร้างหนึ่งครั้ง
- เหมาะที่สุดสำหรับ
- คอนเซปต์ภาพช่วงต้นต้นทุนต่ำ
- อินพุต
- ข้อความ
- เอาต์พุต
- รูปภาพ
- เครดิต
- เริ่มต้น 1 เครดิตต่อการสร้างหนึ่งครั้ง
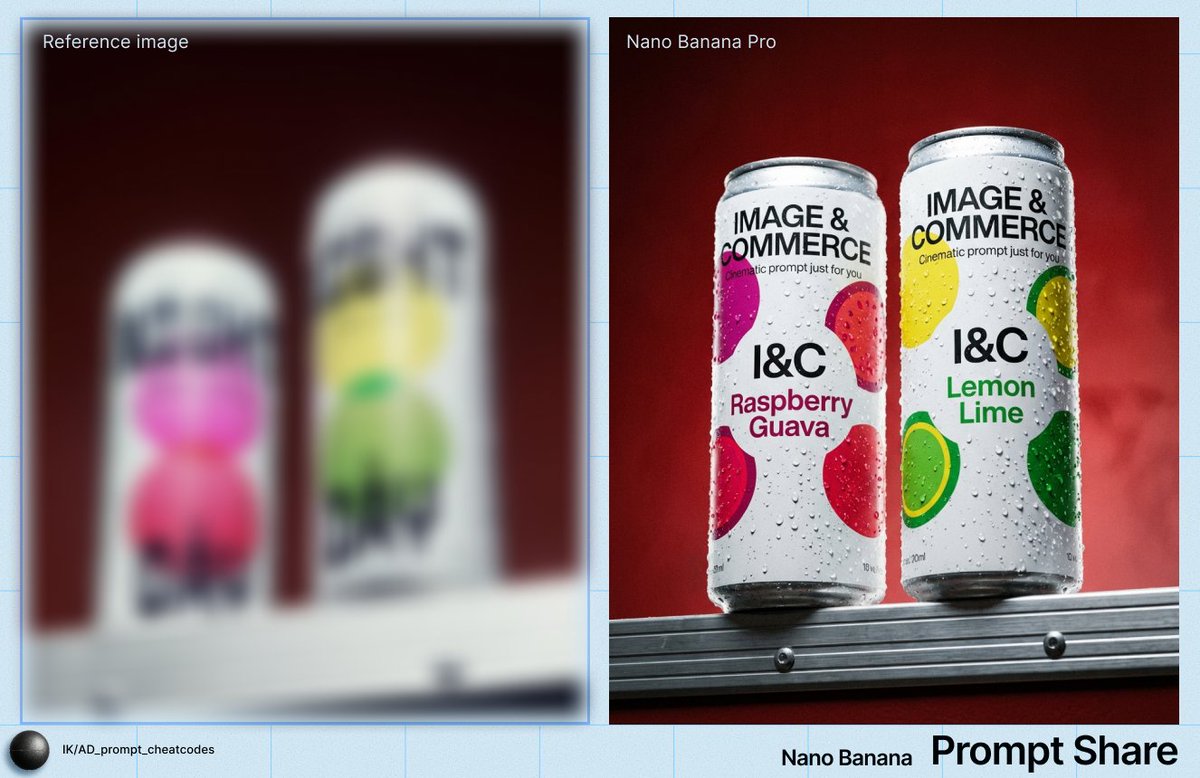
ผลลัพธ์ภาพเดี่ยวที่รวดเร็วสำหรับการวนลองเร็วtext-to-image ที่สะอาดพร้อมพรีเซ็ตอัตราส่วนภาพ 5 แบบ