Alibaba
Z-Image
Immagine
Il modello text-to-image leggero di Alibaba. Generazione rapida di una singola immagine con 5 rapporti d'aspetto, ideale per bozze concettuali veloci e visual social a solo 1 credito.
Perché sceglierlo
Costo più basso a 1 credito per generazione
- Ideale per
- Concept visuali iniziali economici
- Input
- Testo
- Output
- Immagine
- Crediti
- Da 1 credito per generazione
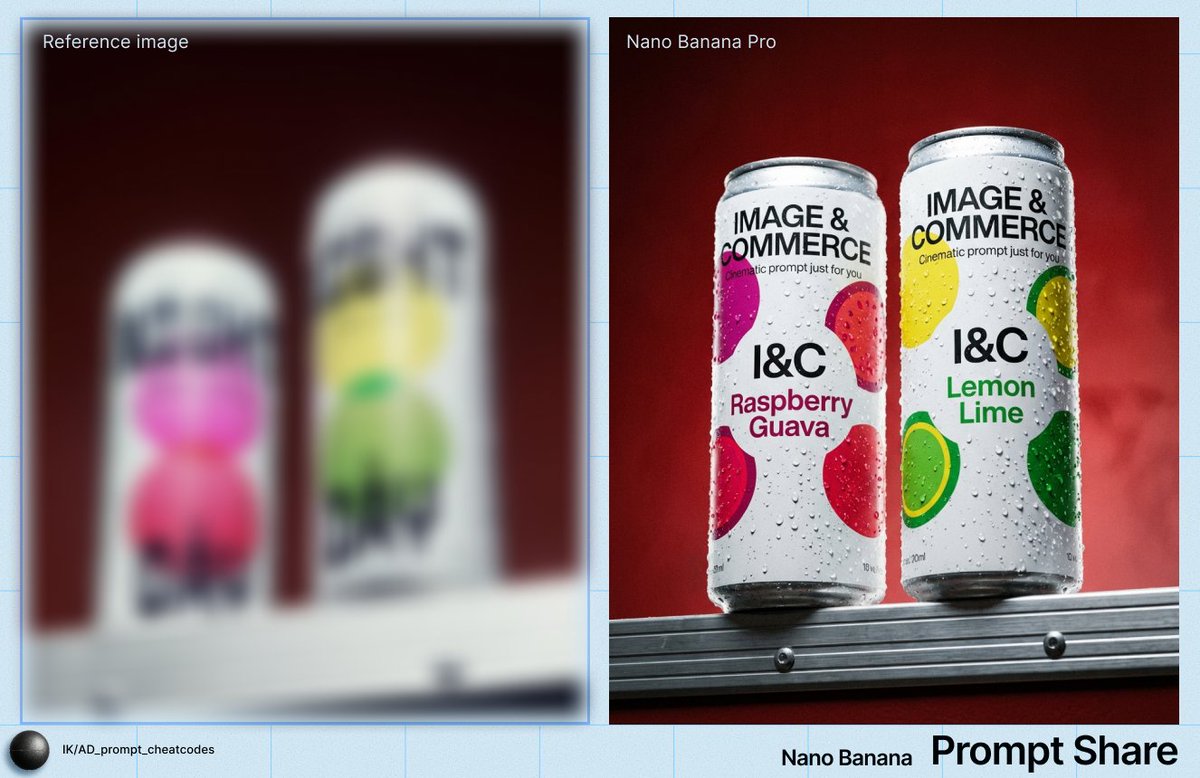
Output rapido a immagine singola per iterazione veloceText-to-image pulito con 5 preset di rapporto d'aspetto